You read a conversion blog on a Sunday night, decide your add-to-cart button should be green instead of black, push the change live on Monday, and by Friday your sales look about the same. So you shrug, call it a win because nothing broke, and move on. That is not testing. That is decorating.
What’s in This Article
Most Aussie Shopify founders run their store on a stack of confident guesses. The homepage hero, the shipping bar copy, the checkout layout, the price point. Every one of those was a decision someone made on a hunch and never checked again. The problem is not a shortage of ideas. It is that almost nobody runs the idea through a process that can actually tell them whether it worked.
Here is the number that should reframe how you think about this. When Optimizely analysed roughly 127,000 experiments across 1,100 companies, only about 12% won on their primary metric. A separate review of more than 28,000 experiments found only around 1 in 5 even reached 95% statistical confidence. Testing is not magic. The brands that compound are not smarter guessers. They just have a system that turns a steady stream of average ideas into a small pile of proven wins, and they let the losers die quietly. This is that system, in five stages.
Stage 1: Build a Hypothesis Backlog From Evidence, Not Opinions
The fastest way to waste a test is to test something you pulled out of a Slack thread. Every experiment should start with a piece of evidence that points at friction. Your job in stage one is to collect that evidence and turn it into a ranked list of things worth testing.
Three sources will fill a backlog for months. Watch where people rage-click, hesitate, and bail using session recordings. Map the full path from ad click to second purchase so you can see which step leaks the most. Ask buyers directly what nearly stopped them. If you have not done this groundwork yet, start with our Shopify Session Recording Playbook and the Customer Journey Mapping Playbook. They are designed to feed exactly this backlog.
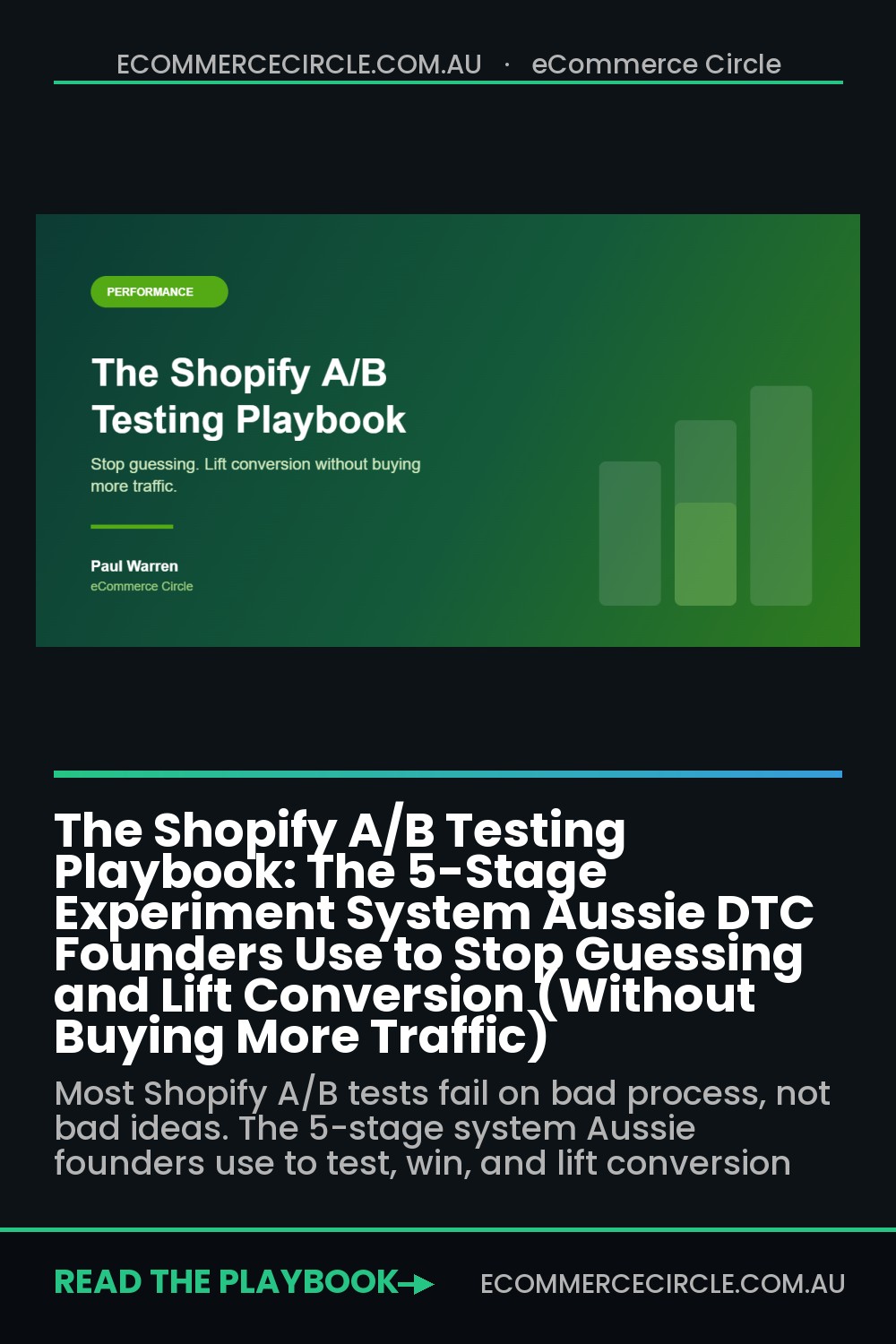
Once you have a list, rank it. The simplest method that survives contact with a busy founder is ICE: score each idea 1 to 10 on Impact (how much revenue could move), Confidence (how sure you are it will work), and Ease (how fast you can ship it). Multiply the three. Highest score goes live first. This stops you spending three weeks testing a footer tweak while the broken mobile cart sits untouched.
Aim for a backlog of at least 15 to 20 hypotheses before you run anything. A deep backlog means you are never idle, never tempted to test something trivial just to feel busy, and always working on the highest-leverage idea you have.
Stage 2: Check You Actually Have the Traffic to Test
This is the stage that saves most stores from a year of meaningless tests. A/B testing only works if you can gather enough data to separate a real effect from random noise. Below a certain traffic level, you literally cannot, and every result you read will be a coin flip dressed up as insight.
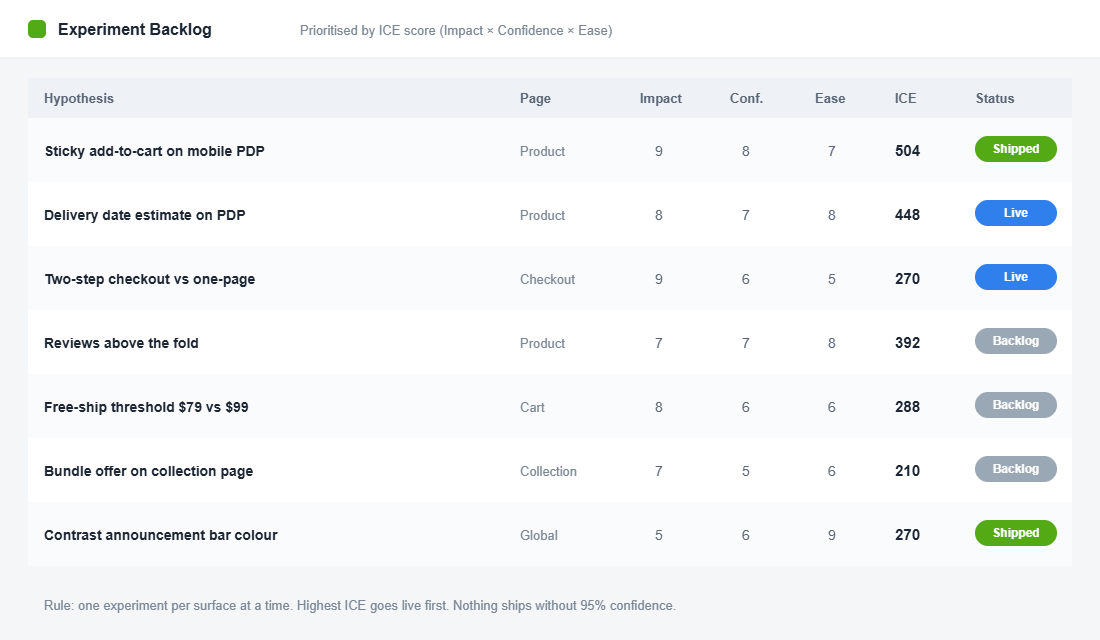
The working rule for a typical product page test is roughly 50,000 monthly sessions on the specific page you are testing, and about 1,000 conversions per variation before you call anything. For a store converting at 2 to 3%, that lands you in the tens of thousands of visitors per variation. The standard you are aiming for is 95% statistical confidence. Anything less and you are guessing with extra steps.
Run your numbers before you build anything. Plug in your baseline conversion rate, the minimum lift you would care about (10% relative is a sensible floor), 95% confidence, and your current traffic. The planner tells you sessions needed per variation and the calendar days that will take. If the answer is 90 days, that test is not viable. Move on.
If you are under that traffic threshold, you are not stuck, you just test differently:
- Test bigger swings. A full page redesign moves the needle far enough to detect on lower traffic. A button colour does not.
- Test higher up the funnel. Your collection and homepage see more sessions than any single product page, so results land faster.
- Test the whole site, not one page. Theme-level tests pool traffic across every page, which gets you to significance quicker than isolating one PDP.
- Fix the obvious first. Below 25,000 sessions a month, you get more value from following CRO best practice than from running underpowered tests.
Stage 3: Write a Hypothesis That Forces a Decision
A real hypothesis is not “let us try a sticky add-to-cart button”. It is a sentence that commits you to a prediction, so the result either confirms it or kills it. Vague intentions produce vague results that everyone interprets to suit themselves.
Use this structure for every test:
Because [evidence from stage one], we believe [this specific change] will cause [this primary metric to move] for [this audience]. We will know we are right when [the metric clears 95% confidence].
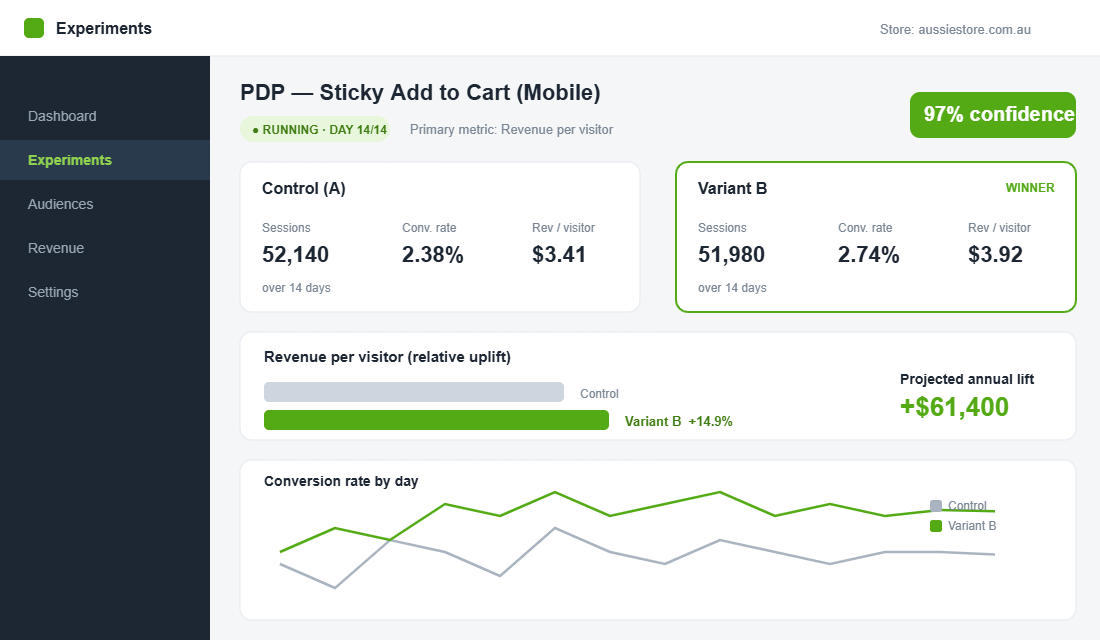
Worked example: “Because 60% of mobile sessions never scroll to the add-to-cart button, we believe a sticky add-to-cart bar will lift revenue per visitor for mobile shoppers. We will know we are right when revenue per visitor clears 95% confidence after two business cycles.”
Notice the primary metric is revenue per visitor, not conversion rate. This matters more than founders expect. A change can lift conversion rate while quietly dropping average order value, leaving you worse off in dollars. Pick one primary metric, make it a revenue metric where you can, and decide the win condition before the test starts. Conversion rate, AOV, and add-to-cart rate are useful supporting metrics, but you ship or kill on the one number you named upfront.
Stage 4: Run It Clean (Where Most Tests Quietly Break)
You have a ranked backlog, enough traffic, and a sharp hypothesis. Now you have to not sabotage yourself. Three discipline problems wreck more tests than any bad idea ever could.
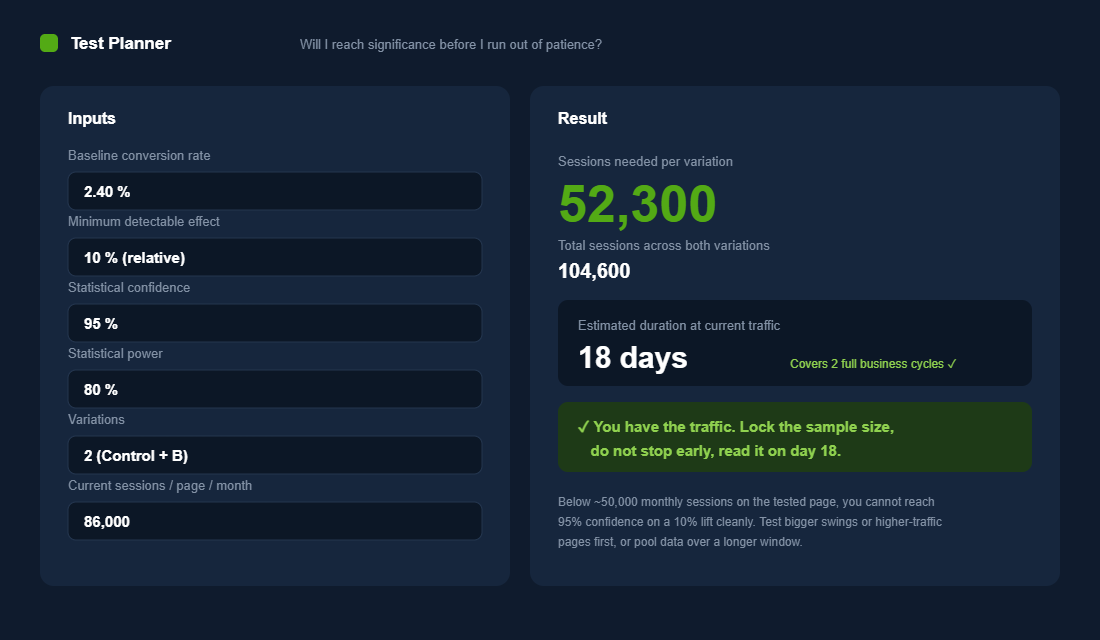
Duration. Run every test for a minimum of two weeks, which covers two full business cycles, and never less than one complete cycle of seven days even if you hit your sample size early. Your Tuesday buyer behaves differently from your Saturday buyer, and payday weeks differ from the dead week before. A test that only saw weekdays is lying to you.
Peeking. This is the silent killer. Checking a running test and stopping the moment it looks good feels responsible. It is the opposite. Repeated peeking inflates your false positive rate brutally: checking results after every 100 visitors can push your real false positive rate to around 55%, more than ten times the 5% you think you are working with. Calculate your sample size upfront, then do not touch the call button until you reach it.
Overlap. Run one experiment per surface at a time. If you are testing the product page layout and the checkout flow simultaneously, and both touch the same shoppers, you cannot cleanly attribute the result to either. One test per surface keeps your data honest.
When a test is set up properly, the read is calm and obvious. Both variations get a near-equal split of traffic, the test runs its full planned window, and you let the confidence level climb to where you said it needed to be before you look for a decision.
Stage 5: Read the Result Like an Operator, Not a Fan
The test is done. Now read it honestly. Three outcomes are possible and all three are useful.
- Clear winner (95%+ confidence, positive primary metric). Ship it to 100% of traffic, document the lift, and bank the learning. Roll the projected annual revenue into your forecast.
- Clear loser or flat. Kill it and keep the control. This is not failure, it is a saved mistake. You just avoided shipping a change that would have cost you money, and you learned something about your customer for free.
- Inconclusive (never reached confidence). Either the effect was too small to matter or you ran out of traffic. Either way, do not ship. Note it and move to the next hypothesis.
Expect to lose more often than you win. Remember the benchmark: only around 12% of experiments win on their primary metric, and roughly 1 in 5 reach significance at all. If most of your tests are “winning”, you are almost certainly peeking, stopping early, or reading noise. A healthy testing programme has a graveyard, and that graveyard is where most of your real learning lives.
Write every result down, winners and losers, in one shared doc: the hypothesis, the change, the dates, the numbers, and the decision. Six months in, that log becomes the most valuable marketing asset you own, because it is a record of what is actually true about your customers rather than what you assumed.
The Tools: What to Use on Shopify in 2026
You do not need an enterprise testing suite to start. You need a tool that splits traffic cleanly, holds the variant stable for each visitor, and reports significance properly. A few options cover most Aussie DTC stores:
- Intelligems. Element and offer level. Strongest pick when you want to test prices, free-shipping thresholds, and promotions, which native Shopify testing cannot touch.
- Shoplift. Theme level. You duplicate a theme, change the variant, and serve it to a test population. Its models estimate significance in real time, which helps you plan duration. Good when you want to test whole-page or multi-section changes.
- Convert or VWO. Cross-channel platforms worth it once you are testing across more than just Shopify, or need advanced targeting and integrations.
A clean first setup with a theme-level tool looks like this: duplicate your live theme, make the single change your hypothesis calls for in the duplicate, connect the tool, set the traffic split to 50/50, set your primary metric to revenue per visitor, lock the planned end date based on your sample-size maths, and walk away until that date. Shopify added native experiment features, but they remain limited on reporting and statistical rigour, so a dedicated tool is still worth the spend once you are testing seriously.
What to Test First: Ideas That Have Actually Moved Numbers
Start where the evidence and the money concentrate: the product page and the checkout. These real results from DTC stores show the kind of swing worth chasing, and double as inspiration for your stage-one backlog:
- Delivery date on the product page. Adding a “Get it by [date]” estimate to the PDP lifted conversion rate by 36% in one Shopify test. Certainty about arrival removes a real objection.
- Sticky add-to-cart on mobile. Footwear brand Oliver Cabell tested a redesigned mobile category page and saw a 10.17% lift across 60,000 visitors and nearly 5,000 orders.
- Checkout structure. A simplified two-step checkout cut cart abandonment by 15% for one store, worth around $57,000 in extra monthly revenue.
- Contrast on key elements. Salty Captain made their announcement bar higher contrast and lifted conversion rate 13.39% and revenue 4.88%, on top of far more clicks on the bar itself.
- Product page social proof. Gymshark has reported lifts around 25% from product page optimisation. Where reviews sit relative to the add-to-cart button is a high-value test on most stores.
Notice none of these are font tweaks. They are changes that remove a real objection or surface a real reason to buy. That is the pattern worth copying. For the full anatomy of a page worth testing on, pair this with our Shopify Product Page Conversion Playbook.
The Compound Effect: Why This Beats Chasing Traffic
Here is where the system pays off. Say you run one solid test a month. Roughly a quarter of them win, which is a realistic rate for a disciplined programme. Each winner lifts revenue per visitor somewhere between 10 and 15%. That sounds modest in isolation.
Now stack it. Three wins a year, each compounding on the last, and you have meaningfully lifted the revenue you earn from every single visitor who was already coming to your store. You did not raise your ad spend by a dollar. You did not chase a new channel. You made the traffic you already pay for worth more, permanently, and every future campaign now pours into a store that converts harder than it did last quarter.
That is the quiet advantage of operators who test. While their competitors burn cash buying more clicks to paper over a leaky funnel, the testers are sealing the leaks one validated change at a time. Same traffic, more orders, better margin. The compounding never shows up in a single dramatic month. It shows up in the year-on-year numbers that make a brand look unstoppable.
Turn One Test Into a Testing Habit
A single test is a curiosity. A testing rhythm is a growth engine. The gap between the two is not budget or tooling, it is cadence. The stores that compound treat experimentation like a fixed monthly ritual, not a thing they get to when the quarter is quiet, which it never is.
Set a realistic pace. For a store doing $40k to $200k a month, one well-run test live at all times is the sweet spot. You are limited by traffic, not ideas, so trying to run four tests at once just means four underpowered tests that all finish inconclusive. One clean test that reaches significance beats four muddy ones every time.
Give it an owner and a slot. Block 30 minutes every Monday to check whether the live test has hit its end date, and an hour at month end to read the result, ship or kill it, log the outcome, and launch the next idea off the top of your ICE-ranked backlog. That single hour a month, repeated, is what separates a brand that knows why it converts from one that is still guessing two years in. The cadence matters more than any individual test, because it is the cadence that turns a pile of average ideas into a compounding stack of proven wins.
Your A/B Testing Starter Checklist
Run this before you launch your next test:
- Hypothesis is backed by evidence from recordings, journey maps, or surveys, not opinion
- Idea scored and ranked against your backlog using ICE
- Tested page has roughly 50,000+ monthly sessions, or you have chosen a bigger swing
- Sample size and required duration calculated upfront
- One primary metric named, ideally revenue per visitor, with the win condition written down
- Test scheduled to run a minimum of two business cycles
- Calendar reminder set for the end date, and a promise to yourself not to peek
- Only one experiment running per surface
- A shared results log ready to record the outcome, win or lose
Inside eCommerce Circle, building a real testing programme is one of the core pillars we work on with every member, because it is the single most reliable way to grow profit without growing spend. If you want a second opinion on what to test first in your store, let’s talk.